友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
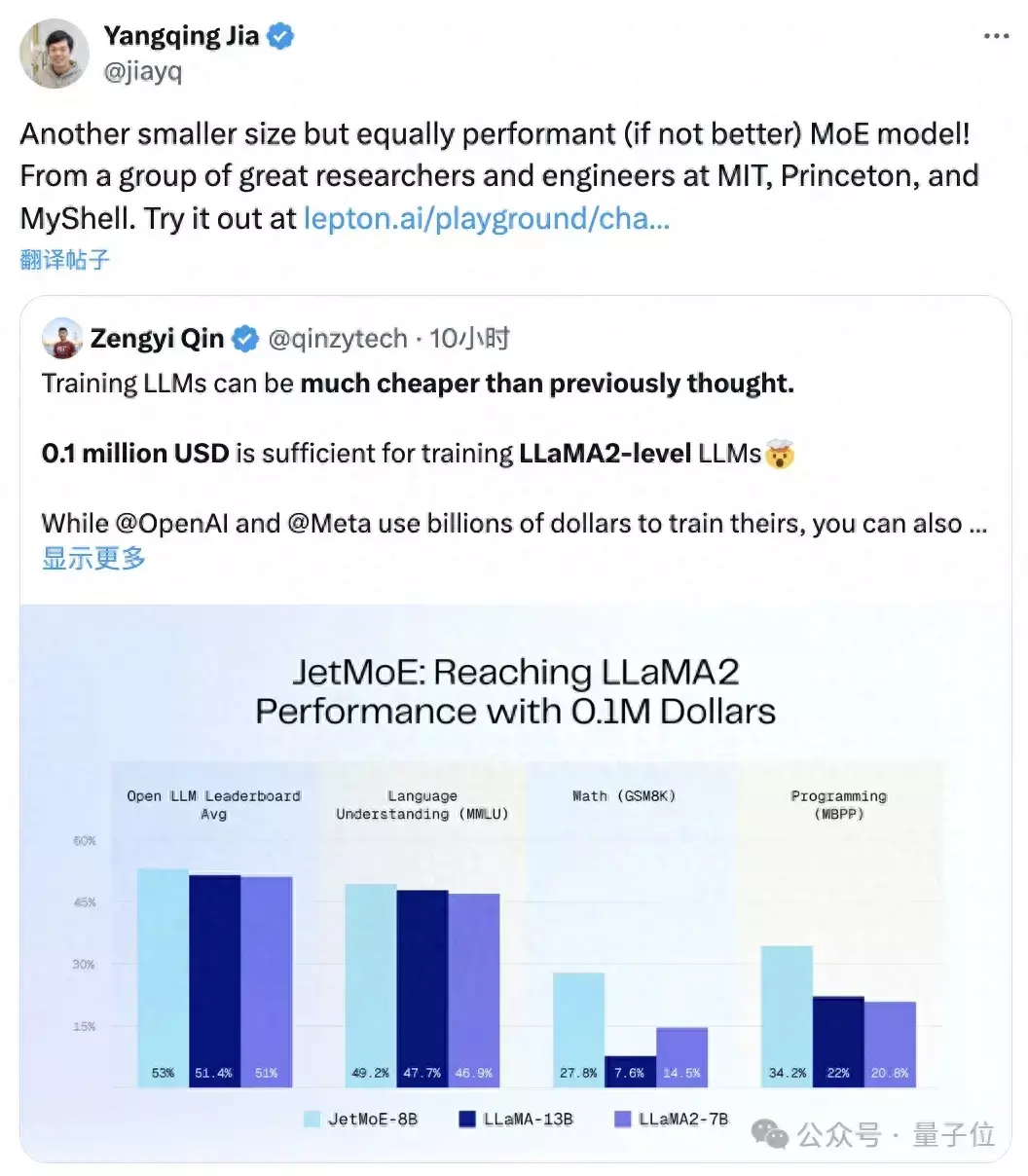
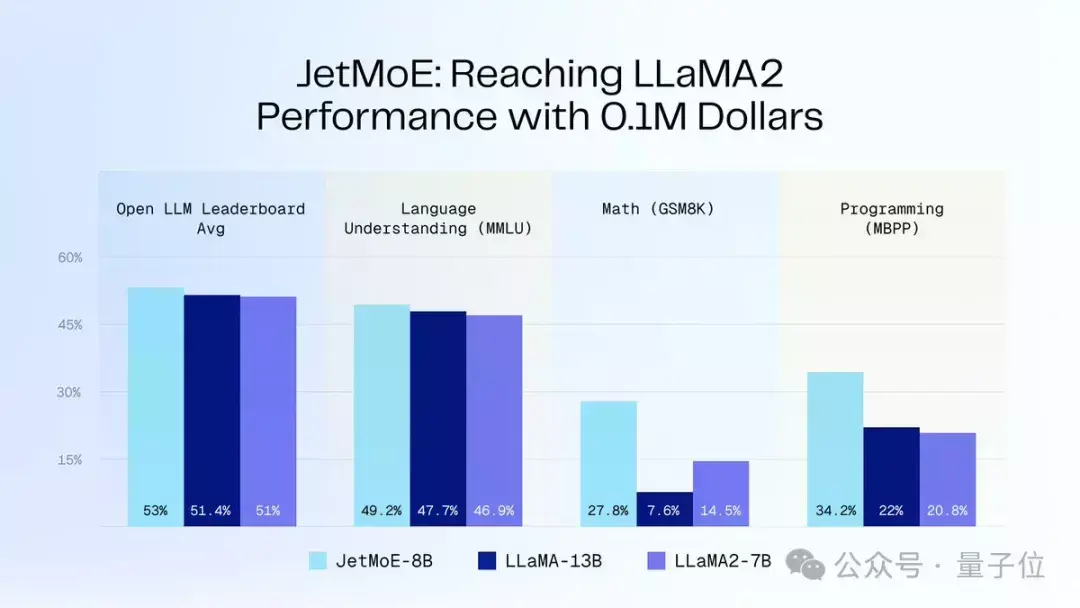
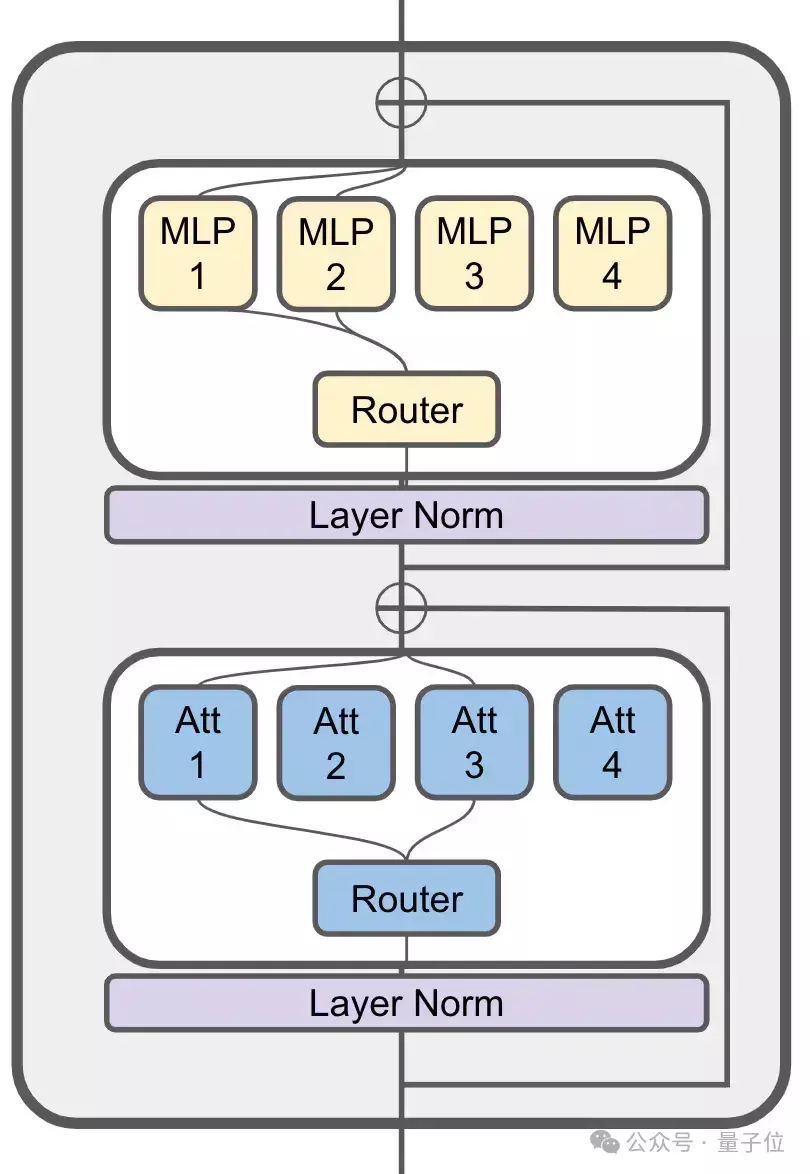
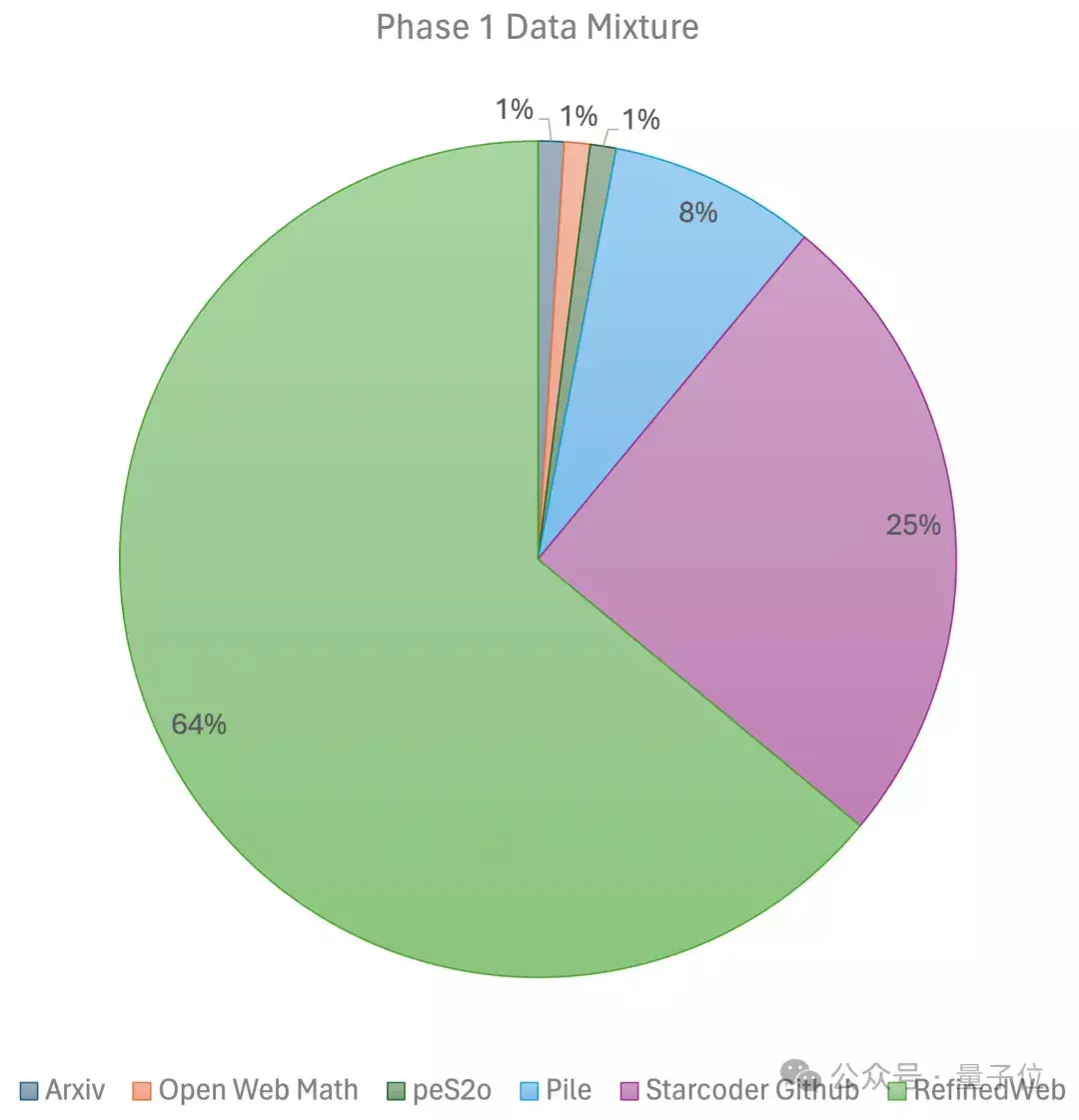
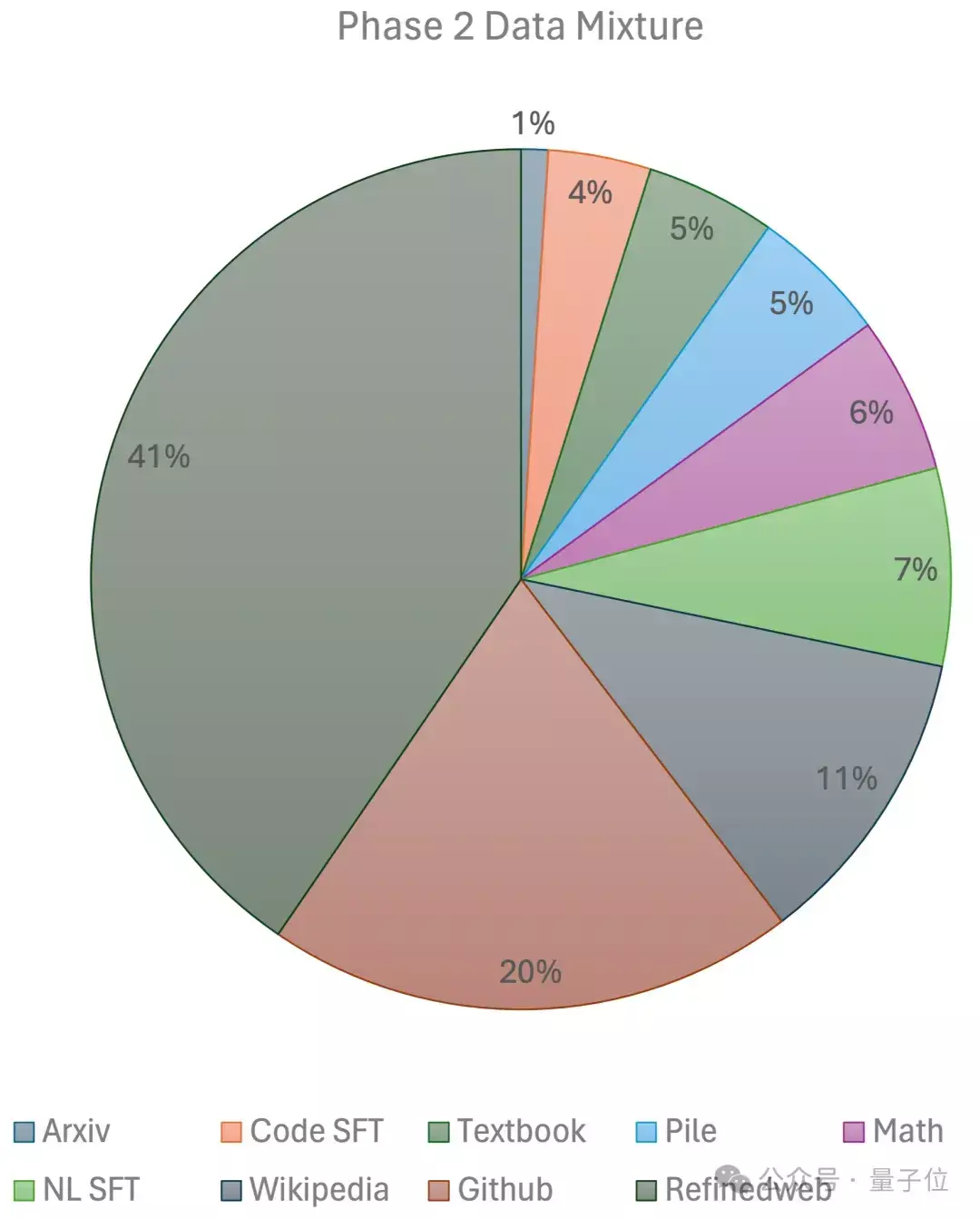
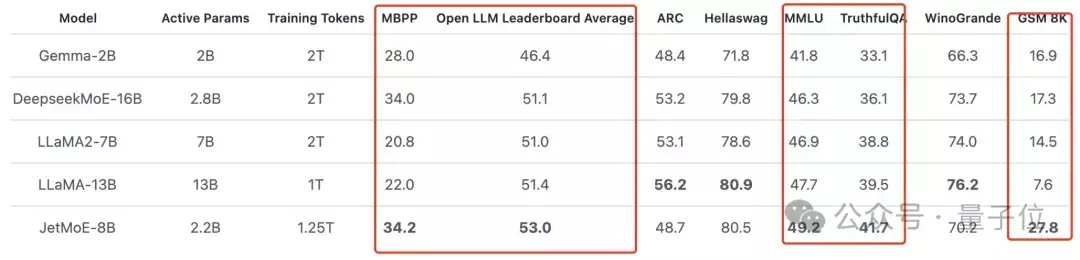
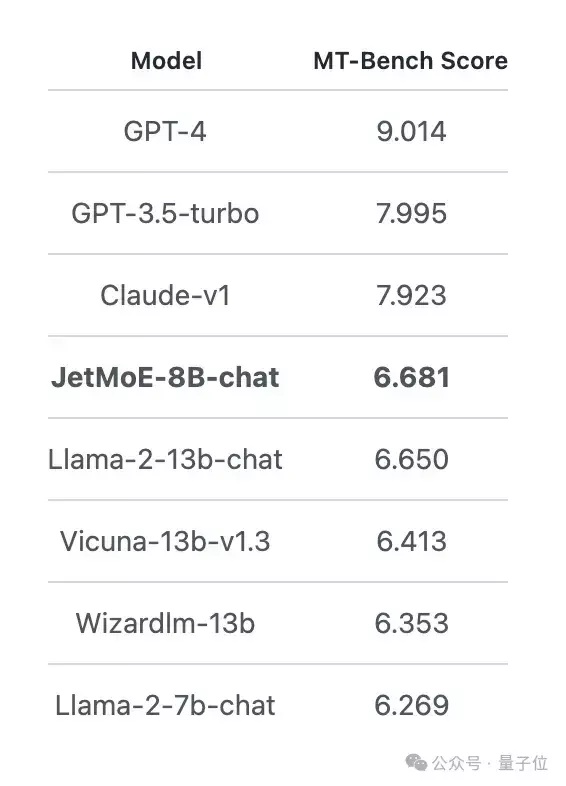
10万美元训出Llama-2级大模型!全华人打造新型MoE,贾扬清围观
38
0
相关文章
近七日浏览最多
最新文章
标签云
大连
思科
华为
赔偿
ibm
科技巨头
裁员风暴
中国
裁员
运营
公司
研发部门
陈旭东
ibm公司
微软
谷歌
李开复
融资
a股
巴菲特
美联储
价值投资
伯克希尔哈撒韦
资本市场
libra
麻省理工学院
人工智能
德国
gartner
人工智能技术
股票
小盘股
美股
达摩院
阿里
自由现金流
股价
f16
航空航天
初创公司
英伟达
kris
英特尔
科技
芯片
清华大学
摩托罗拉
美国
数字经济
中国中车
智联
物联网
中国航天科技
世界经济
500强
家得宝
板块
java
职场
比尔盖茨
投资
alphabet
日本
世界知识产权组织
阿里巴巴集团
中国平安
谅解备忘录
协会
天使轮
adc
京东金融
拼多多
京东
京东快递
科创板日报
高盛
马斯克
戴尔
超级计算机
麦当劳
快餐
机器学习
azure
凯瑟琳
米歇尔
普林斯顿
巴拉克
杨振宁
西南联大
毕业生
本科
诺贝尔奖
北京队
篮球
中国队
球队
国际篮联
成都
翁帆
诺贝尔
住宅
丰田
SUV
丰田汽车
tnga
suv车型
一树梨花压海棠
计算机科学
gpu
mit
教授
演讲
南昌大学
颜宁院士
中国工程院院士
美国海军
黄仁勋
埃利奥特
史蒂文斯
时代周报
应收账款
太阳能电池
郑州
苹果
富士康
rain
游戏
机器人
cpu
jonathan
john
rtx
显卡
归母净利润
快科技
npu
处理器
研报
第一财经
ows
matebook
oled
笔记本电脑
ultra
独立显卡
骁龙
高通
光伏发电
adobe
soc
三星
联发科
联发科天玑
siri
ios
mac
iops
pdd
pi
arm
心理健康
哈佛
中国科技大学
计算机系
新加坡国立大学
麻省理工
郭艾伦
nba
36氪
天眼查
睡眠质量
中国大学
中南财经政法大学
高校
斯坦福
上海交大
gpa
学霸
基金会
华裔
sora
回国效力
OpenAI