编辑部 整理自 凹非寺
量子位 | 公众号 QbitAI
一支人大系大模型团队,前后与OpenAI进行了三次大撞车!
第一次是与Clip,第二次是与GPT-4V,最新一次撞在了Sora上:
去年5月,他们联合并联合伯克利、港大等单位于在arXiv上发表了关于VDT的论文。
那时候,该团队就在在技术架构上提出并采用了Diffusion Transformer。并且,VDT还在模型中引入统一的时空掩码建模。
这个团队,正由中国人民大学高瓴人工智能学院教授卢志武带队。
Sora问世已经两个多月,现在这支国产团队在视频生成领域的进度怎么样了?什么时候我们能迎来国产Sora的惊艳时刻?
在本次中国AIGC产业峰会上,卢志武对上述问题进行了毫无保留的分享。

为了完整体现卢志武的思考,在不改变原意的基础上,量子位对演讲内容进行了编辑整理,希望能给你带来更多启发。
中国AIGC产业峰会是由量子位主办的行业峰会,20位产业代表与会讨论。线下参会观众近千人,线上直播观众300万,获得了主流媒体的广泛关注与报道。
话题要点
- VDT使用Transformer作为基础模型,能更好地捕捉长期或不规则的时间依赖性;
- Scaling Law是视频生成模型从基于Diffusion model转向基于Transformer的重要原因;
- VDT采用时空分离的注意力机制,而Sora采用时空合一的注意力机制;
- VDT采用token concat方式,实现快速收敛和良好效果;
- 消融实验发现,模型效果与训练消耗的计算资源正相关,计算资源越多,效果越好;
- 只要拿到更多算力,超过Sora也不是那么难的事。
……
以下为卢志武演讲全文:
为什么做视频生成突然要转到用Transformer上?
今天的报告,我将重点介绍我们在视频生成领域的工作,特别是VDT(Video Diffusion Transformer)。
这项工作已于去年5月发布在arXiv上,并已被机器学习顶级会议ICLR接收。接下来,我将介绍我们在这一领域取得的进展。
众所周知,Sora非常出色,那么它的优势在哪里呢?之前,所有的工作都是基于Diffusion Model,那为什么我们在视频生成中突然转向使用Transformer呢?
从Diffusion到Transformer的转变,原因如下:
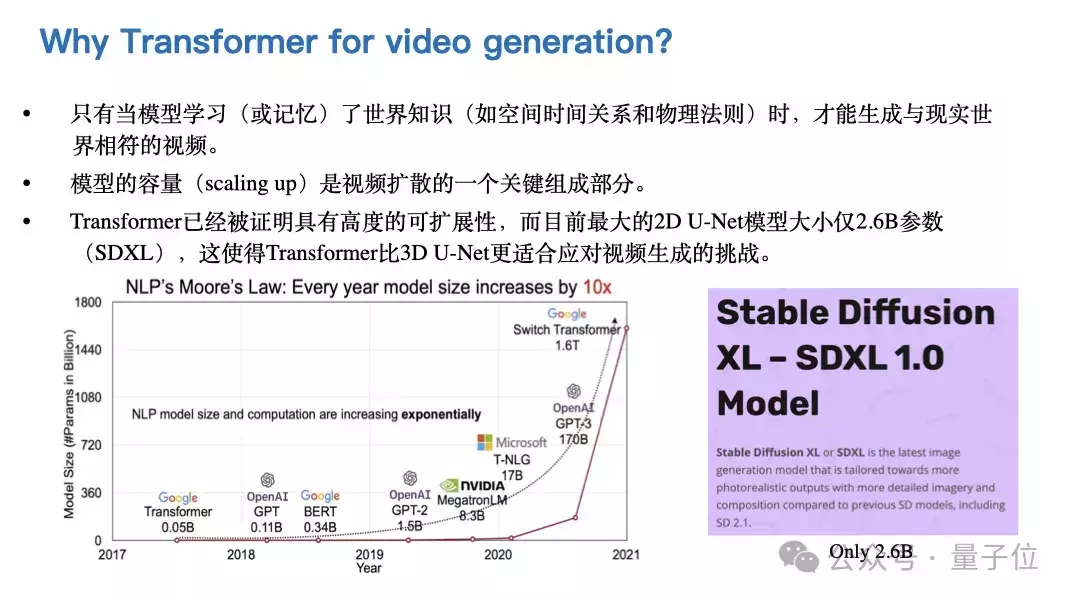
与基于U-net的Diffusion模型不同,Transformer具有许多优点,如token化处理和注意力机制,这两个特点使其能够更好地捕捉长期或不规则的时间依赖性。因此,在视频领域,许多工作开始采用Transformer作为基础模型。
然而,这些都是表面现象,最根本的原因是什么呢?使用Transformer进行视频生成,是因为其背后的scaling law发挥了作用。
Diffusion Model的模型参数量是有限的,而一旦将Transformer作为基础模型,参数量可以随意增加,只要有足够的计算能力,就可以训练出更好的模型。实验证明,只要增加计算量,效果就会得到提升。
当然,视频生成涉及各种任务,使用Transformer能够将这些任务统一在一个架构下。
基于上面三个原因探索用Transformer当视频生成的底座,这是我们当时的考虑。
我们的创新点有两个:
一是将Transformer应用于视频生成,并结合了Diffusion的优点;二是在建模过程中,我们考虑了统一的时空掩码建模,将时间和空间置于同等重要的位置。
无论是VDT还是Sora,第一步都是对视频进行压缩和token化处理。
这与基于DM的方法最大的区别在于,基于DM的方法只能进行空间压缩,无法进行时间压缩;而现在,我们可以同时考虑时间和空间,实现更高的压缩程度。
具体来说,我们需要训练一个时空空间中的3D量化重构器,这可以作为tokenizer,得到三维空间中的patches。
总之,通过这种方式,我们可以得到Transformer的输入,输入实际上是3D的tokens。
一旦我们将输入的视频进行token化处理,就可以像通常的Transformer一样,使用标准的Transformer架构对3D的token序列进行建模,细节我就不赘述了。
VDT和Sora有什么差别?
VDT模型中最重要的部分是时空的Transformer Block。
我们与Sora有一点不同,当时设计这个Block时,我们将时空的Attention分开了。高校团队没有OpenAI那么多的计算资源,这样分开后,所需的计算资源会少很多——除此之外,其他所有设计都一模一样。

现在,让我们来看看我们与Sora的区别。
刚才我说过,VDT采用了时空分离的注意力机制,空间和时间是分开的,这是在计算资源有限的情况下的折中方案。
Sora采用的是时空统一的token化,注意力机制也是时空合一的,我们推测Sora强大的物理世界模拟能力主要来自于这个设计。
至于输入条件不同,这不是VDT与Sora最大的区别,基本上图生视频能做好,文生视频也能做好。
文生视频的难度较大,但并非无法克服,没有本质上的差别。
接下来,我将介绍我们当时探索的一些事项。架构设计完成后,我们特别关注输入条件。这里有C代表的Condition Frame,以及F代表的Noisy Frame。
这两种输入条件应该如何结合,我们探索了三种方式:
- 通过Normalization的方式;
- 通过token concat的方式;
- 通过Cross attention。
我们发现,这三种方式中,token concat的效果最佳,不仅收敛速度最快,而且效果最好,因此VDT采用了token concat方式。
我们还特别关注了通用时空掩码机制。
不过,由于Sora没有公布细节,我们不清楚它是否也采用了这个机制,但在模型训练过程中,我们特别强调了设计这样的掩码机制,最终发现效果非常好,各种生成任务都能顺利完成——我们发现Sora也能达到类似的效果。

消融实验特别有趣,无论是Sora还是VDT,有一个非常重要的问题,就是模型中有大量的超参数,这些超参数与模型密切相关,不同的参数会对模型的效果产生很大影响。
然而,通过大量实验验证,我们发现超参数的选择有一个规律,即如果超参数使得模型的训练计算量增加,那么对模型效果是有益的。
这意味着什么?我们模型的性能只与其背后引入的计算量有关,模型训练所需的计算资源越多,最终的生成效果就越好,就这么简单。
这个发现与DiT类似,DiT被称为Sora的基础模型,它是用于图片生成的。
总之,消融实验是Sora或我们工作中最重要的事情之一,我们模型的效果只与训练消耗的计算资源有关,消耗的计算资源越大,效果越好。
有更多算力,超过Sora不是太难
考虑到我们的计算资源确实有限,我们团队在模型训练规模上,肯定不能与OpenAI相比。但是,我们也进行了一些深入的思考。
物理世界模拟本身就在我们的论文中,并不是说这是OpenAI首先想到的,我们一年前就想到了。
当时有这个底座以后,很自然想到这样模型到底能不能进行物理规律模拟。后来在物理数据集上训练了一下VDT,发现它对简单的物理规律模拟得特别好。
比如,这些例子有抛物线的运动,加速运动,还有碰撞的运动,模拟得都还可以。

所以我们当时做了两个在思想上特别有前瞻性的事情,一个是当时我们想到Diffusion Transformer用到视频生成里面,第二个是我们得到了这样模型以后,我们当时觉得这就是做物理世界模拟很好的模型,我们做实验验证了这个事情。
当然,如果我们有更多的算力,我们有更多的数据,我相信肯定可以模拟更复杂的物理规律。
我们这个模型也跟现在有模型做了对比,比如人像生成,给一张写真的照片让它动起来,我们只考虑做这个小的事情,因为我们算力特别有限。
这些结果表明VDT比Stable Video Diffusion要好一些,你可以看看生成得人物眼睛眨的更明显一些,更自然一点。另一个模型生成有点不太自然。
此外,如果人脸从侧面转成正脸,甚至用扇子把脸遮住了,要把人脸预测出来,还是挺难的。

关于这个写真视频是怎么做的我简单说一下。
先提供几张写真的照片,VDT把每一张写真照片变成两秒的镜头,通过剪辑的方式把镜头拼在一起。
结合我们团队本身的特点,如果说我做通用的模型,我肯定做不过市面上的大部分,但是我当时挑了一个应用点,在这个点上VDT并不比Sora差。
Sora出来以后很多人要做视频生成,我要考虑怎么保证我的团队在这个方向上,哪怕很小的一个点保持世界最前沿。
因此,我们做了写真视频生成,国外的Pika、Sora也研究了一下。VDT生成的超写实人物,是超过Pika和Sora的。在通用的视频生成我们很难超过Sora,这里的主要原因是我们算力很有限。
只要拿到更多算力,超过Sora也不是那么难的事。
我就讲这么多,谢谢大家。
— 完 —
量子位 QbitAI · 头条号签约
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com