当前大家常见的视频生成是酱婶儿的:

多数情况下只能让一个人动起来。
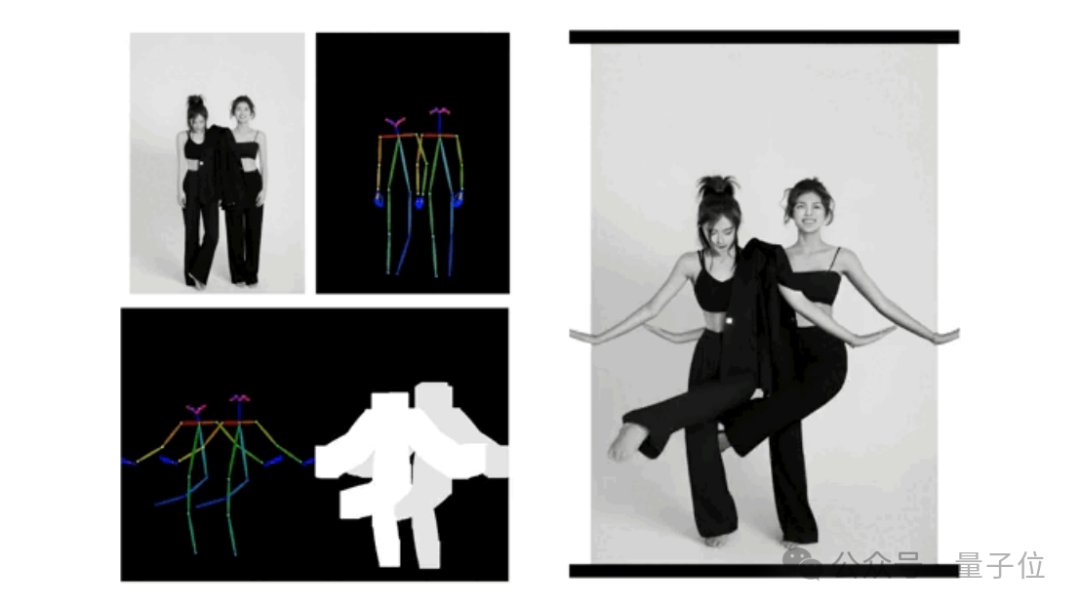
而现在,如果提供了一张人物合照,所有人都能同时“舞起来了”。

如此看来,从单人到多人,视频生成已经进入了Next Neval ~
如上成果出自腾讯混元团队联合中山大学、香港科技大学推出的全新图生视频模型:Follow-Your-Pose-v2。

与之前的模型相比,“Follow-Your-Pose-v2”主要有4大新亮点:
- 在推理耗时更少的情况下,支持多人视频动作生成
- 模型具备较强的泛化能力,不论年龄、服装、人种、背景杂乱程度、动作复杂程度如何,都能生成高质量视频
- 日常生活照(含抓拍)/视频均可用于模型训练及生成,无需费力寻找高质量图片/视频
- 面对单张图片上多个人物的躯体相互遮挡问题,能生成具有正确前后关系的遮挡画面,保证多人“合舞”顺利完成
为了评估多角色生成效果,团队提出了一个包含约4000帧(约20个多角色视频)的新基准——Multi-Character。
实验结果显示,模型在2个公共数据集(TikTok和TED演讲)和7个指标上的性能均优于最新技术35%以上。

下面,一起来看看它具体是如何做到的吧。
怎么做到的?
目前,Follow-Your-Pose-v2已经能很好地完成“单人动起来”这项任务(生成视频长度可达10秒)。
它的出现主要用来解决“更复杂场景”可能遇到的视频生成问题:
- 多个角色动画
- 多角色身体遮挡、背景畸变等一致性问题
- 传统方法下的训练数据集要求高(不易获取且成本高)
首先,在动作驱动图片生成视频的任务中,一般的方法往往需要精心筛选高质量(具有稳定背景和时间一致性)训练数据,成本高的同时还限制了训练集的规模,从而导致模型在泛化能力的提升上有瓶颈。
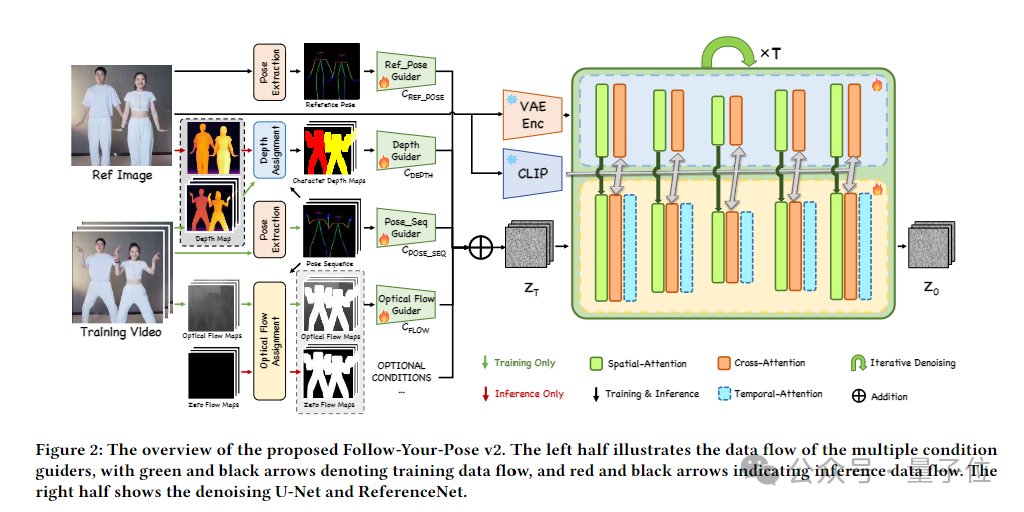
对此,团队提出了一个可以在互联网上容易获得的嘈杂开源视频上进行训练的框架Follow-Your-Pose v2。
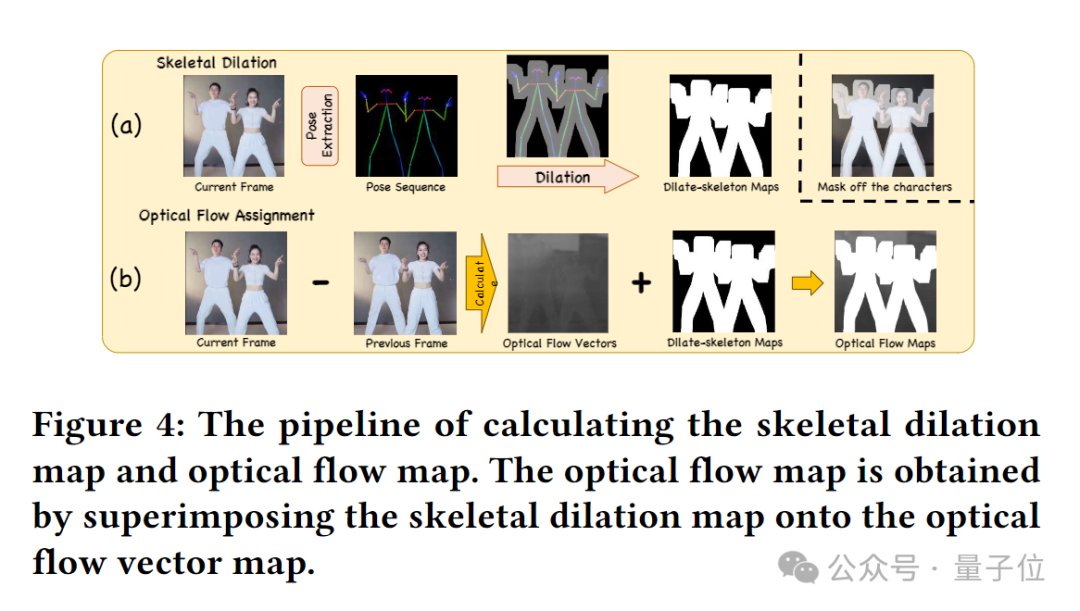
该框架中特有的“光流指导器”(Optical Flow Guider)引入了背景光流信息,赋予了模型在大量有噪声的低质量数据上训练收敛的能力。
具体而言,光流指导器负责分析并预测帧间的像素级运动,为模型提供背景稳定性。通过这种方式,即使在存在相机抖动或不稳定背景的情况下,也能生成稳定的背景动画。
这也意味着,“Follow-Your-Pose-v2”能够让使用者基于任意一张人物图片和一段动作视频生成高质量视频,不再需要费力寻找满足高要求的图片和视频,这些照片可以是自己和家人朋友的生活照,也可以是偶像的一张简单抓拍。

其次,模型对于图片上蕴含的空间信息的理解能力有限,具体表现在前景和后景的区分不清晰,导致生成视频背景的畸变和人物动作的不准确。

对此,Follow-Your-Pose-v2框架通过整合多条件引导器(Multi-condition Guiders),有效解决了现有方法在复杂场景下的不足,如多角色动画和身体遮挡问题。
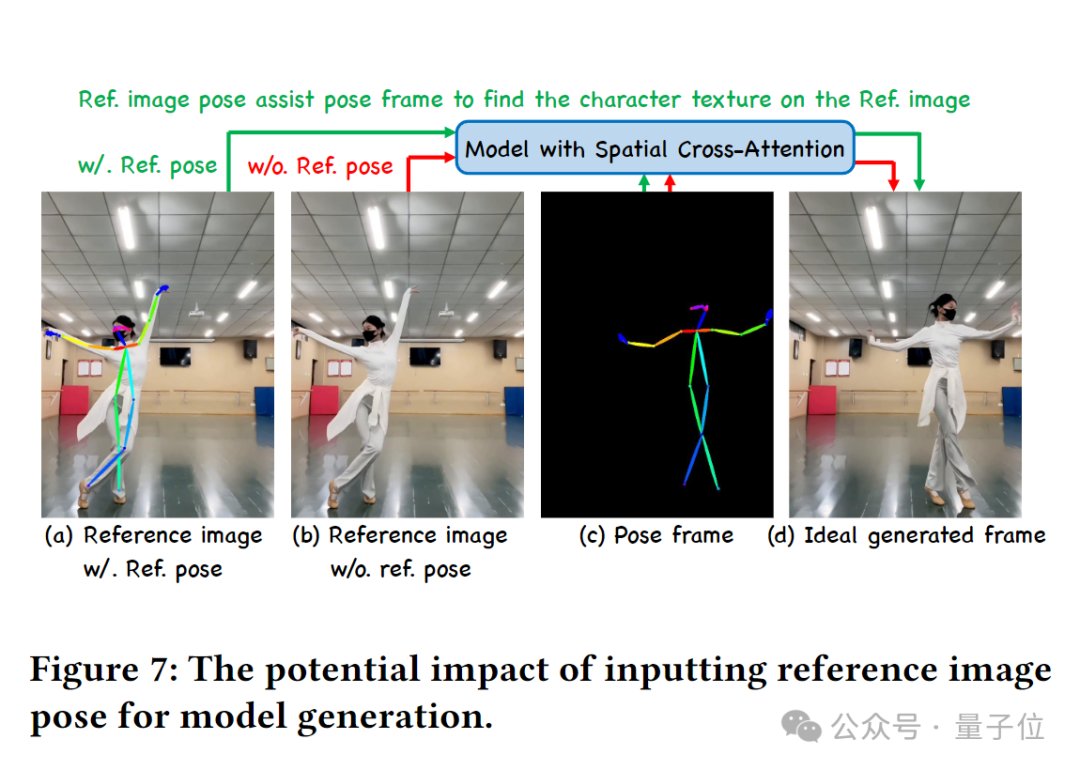
该框架中特有的“推理图指导器”(Reference Pose Guider)引入了图片中的人物空间信息,赋予模型更强的动作跟随能力。
另外,模型特有的“深度图指导器”(Depth Guider)引入了多人物的深度图信息,增强了模型对于多角色的空间位置关系的理解和生成能力。在面对单张图片上多个人物的躯体相互遮挡问题时,“Follow-Your-Pose-v2”能生成出具有正确的前后关系的遮挡画面,保证多人“合舞”顺利完成。
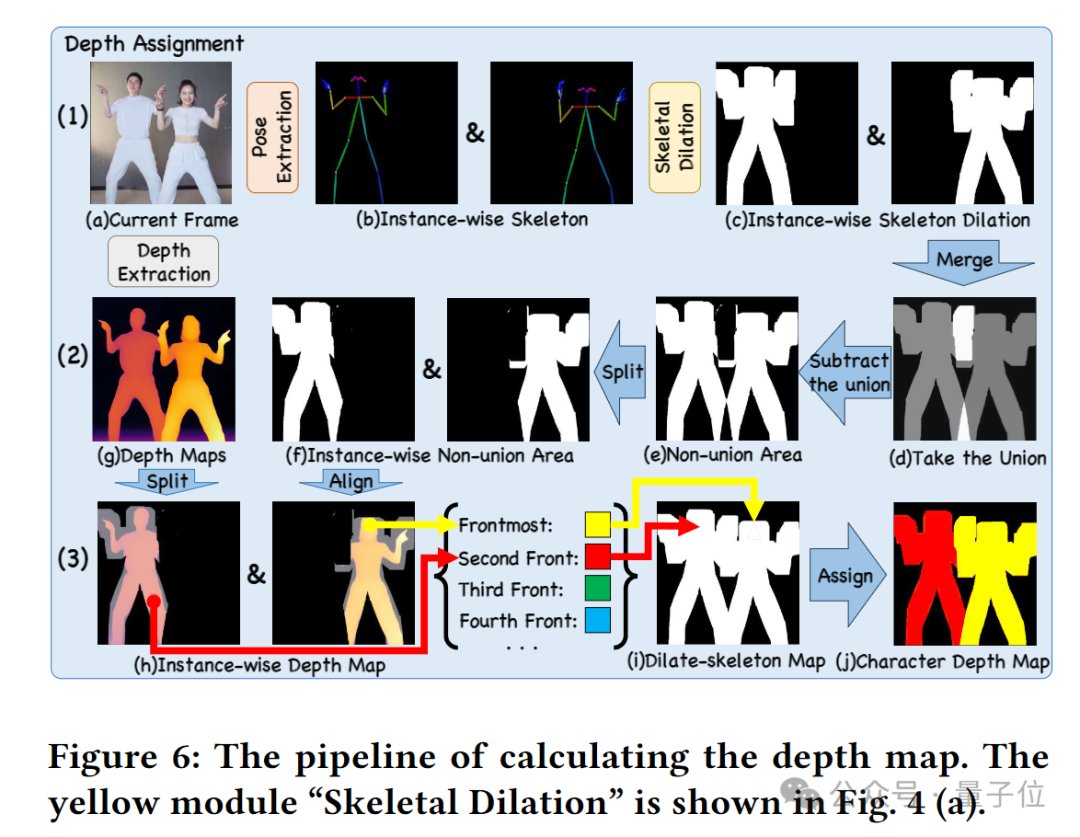
总之,新框架通过整合多种条件引导器,提高了模型对嘈杂数据的鲁棒性,使其能够直接在未经筛选的大量视频上进行训练。
在训练过程中,团队收集了4000个来自TikTok、YouTube和其他网站的公共视频,总计200万帧。
为了评估效果,团队将“Follow-Your-Pose-v2”与多个现有的最先进方法进行了比较,包括基于GAN的方法(如MRAA和TPSMM)和基于VLDM的方法(如DreamPose、DisCo、MagicAnimate和AnimateAnyone)。
并且团队先在TikTok和TED演讲这2个公共数据集上进行了测试。
在TikTok数据集中,模型在姿势跟踪和视觉质量方面获得了更好的性能。比如它能够生成真实情况中不存在的手部细节,以及它是能够准确生成反向举起手臂的姿势的唯一方法。

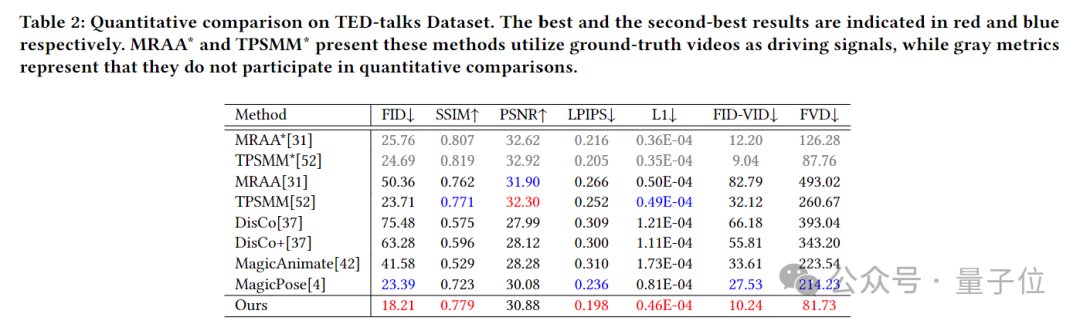
在TED演讲数据集中,模型在除PSNR(衡量图像的峰值信噪比)之外的六个评估指标上都实现了SOTA性能。
此外,由于缺乏多角色视频生成的基准,团队从社交媒体收集了20个多角色舞蹈视频,总计3917帧,命名为Multi-Character。该数据集作为评估模型生成多角色姿态可控视频能力的基准。
可以看到,在Multi-Character Bench数据集上,“Follow-Your-Pose-v2”在所有评估指标上都显著优于其他方法,证明了其在处理多角色动画方面的优势。

最后,为了评估各个组件对整体性能的贡献,团队进行了消融研究,移除了光流、深度图和推理图指导器,分别评估它们对模型性能的影响。
研究表明,光流指导器对模型性能的提升最为显著,其次是深度图引导器和推理图引导器。这些组件的移除都会导致性能下降,证明了它们在生成稳定和高质量动画中的重要性。

One More Thing
当下,图像到视频生成的技术在电影内容制作、增强现实、游戏制作以及广告等多个行业的AIGC应用上有着广泛前景,是2024年最热门的AI技术之一。
参与了“Follow-Your-Pose-v2”研究的腾讯混元团队,也在6月6日公布了其文生图开源大模型(混元DiT)的加速库,号称大幅提升推理效率,生图时间缩短75%。
官方表示,混元DiT模型的使用门槛也大幅降低,用户可以基于ComfyUI的图形化界面使用腾讯混元文生图模型能力,并在Hugging Face的官方模型库中用三行代码调用模型(无需下载原始代码库)。
目前本文介绍的相关技术论文已上传公共社区,感兴趣的家人们可以进一步了解。
论文:https://arxiv.org/abs/2406.03035
— 完 —
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com