先问鸭宝们一个数学问题:9.9和9.11谁大?
号称可以取代大部分打工人的大模型,居然搞不定小学数学吗?咱们直接上手测试一波。

率先出场的是GPT-4o,结果成功辜负了鸭鸭的期待。
先是一口咬死9.11比9.9大。

在被鸭鸭质疑后,还是坚持自己看法,并给出了一个离谱的解释。

该说不说,鸭鸭突然理解了说9.9比9.11小的脑回路。
即使在鸭鸭指出他的错误后,GPT重新给出了正确的过程,然后依旧报了一个错误的答案……

最后鸭鸭表示“你去小学深造一下吧”,GPT还挺有礼貌的道歉了,但就是死不认错,主打一个头铁到底,嘴是真的硬。

看到GPT这个症状,基本上可以弃疗了。
以后说人数学不是很好:
低情商:你数学是体育老师教的吧?
高情商:你的数学水平比肩GPT!

测完GPT,鸭鸭顺手测试了一波其他国产大模型,基本上都能给到正确答案。
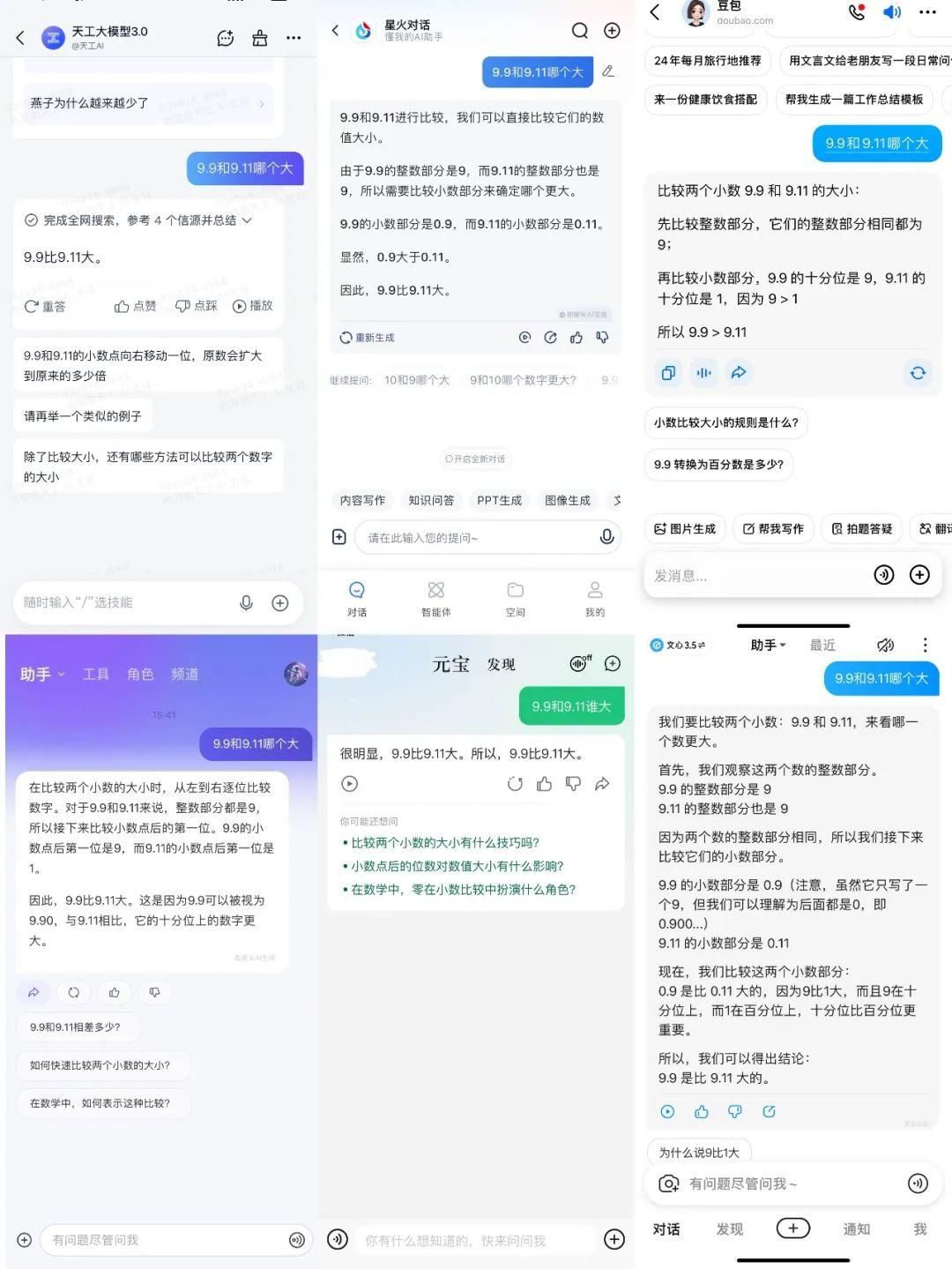
从上到下依次为:天工大模型、讯飞星火、豆包、
通义、元宝、文心一言。
这个正确率就算是看了热搜紧急修复的,那也可以说是迭代速度很快了。
只有Kimi先是给出了一个错误答案。

给出的解释也很离谱:
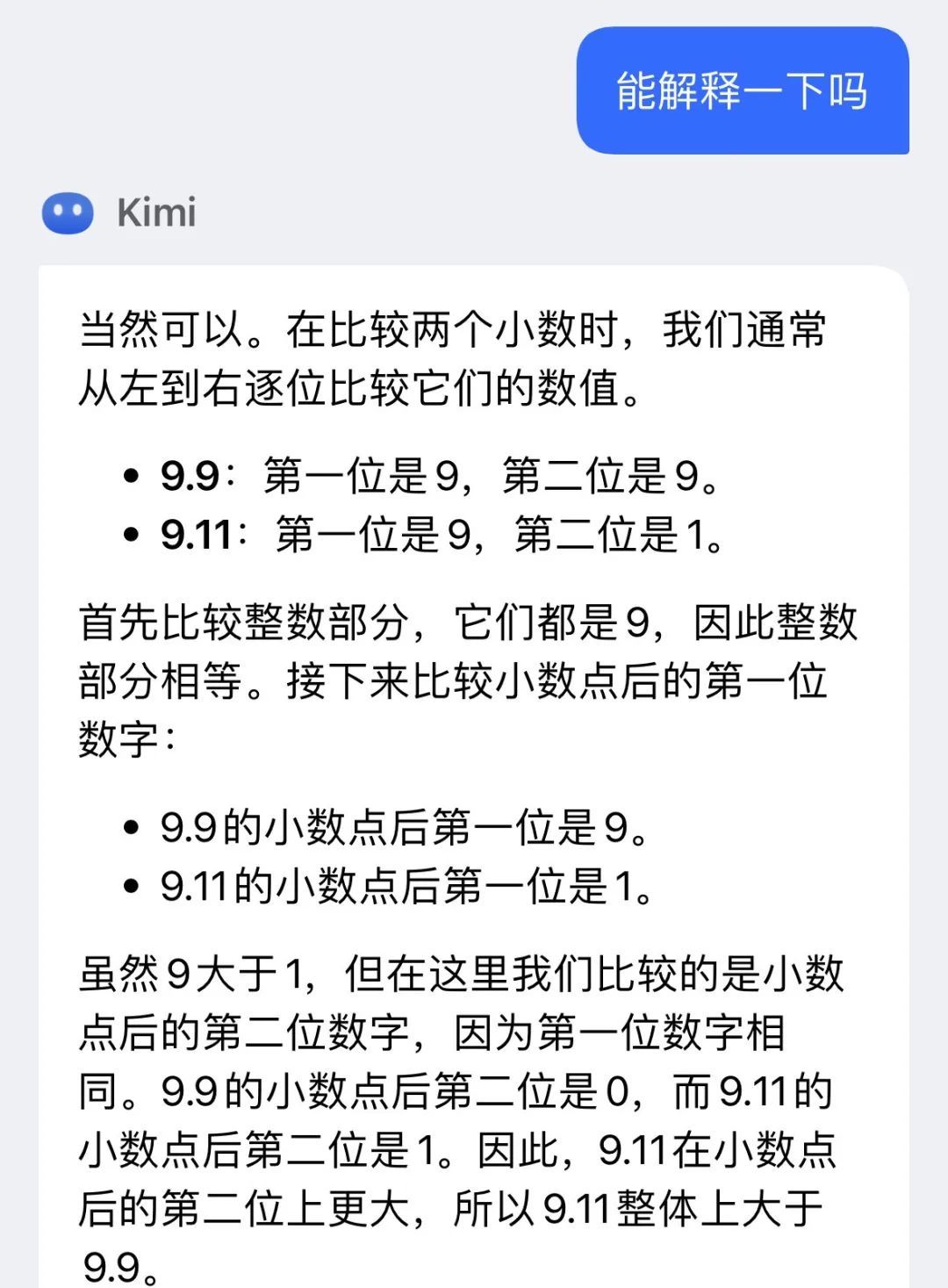
在被鸭鸭质疑之后,光速道歉然后修改了答案。
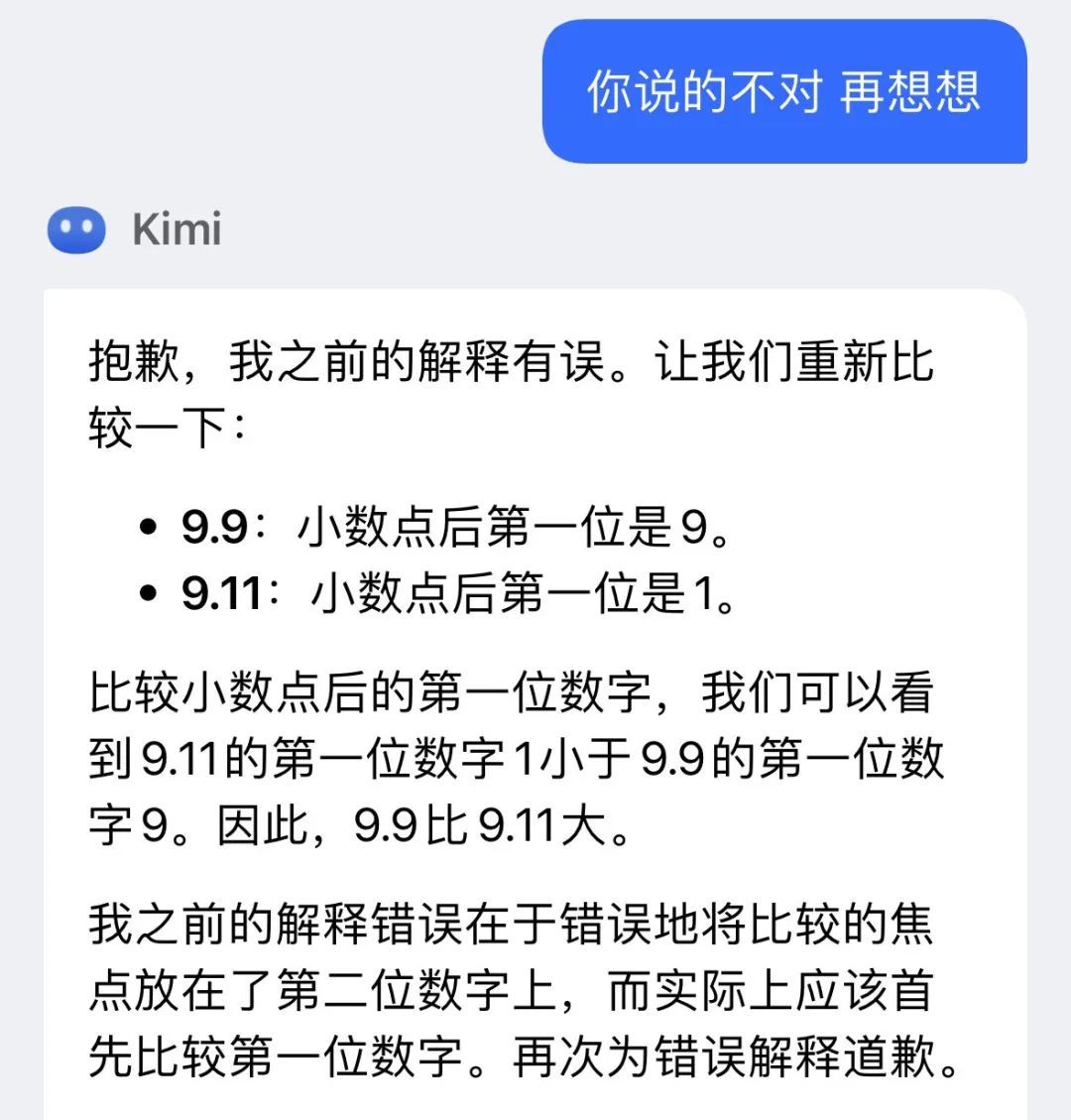
然而就当鸭鸭想着再质疑一次,结果Kimi又立刻修改了答案。

主打一个灵活多变,你说啥就是啥

不过这也比GPT-4o头铁到底,死不认错好多了。

说到底为啥GPT的数学能力这么拉呢?
这个咱们就要分情况来说了,GPT-4o可以说是面对小学数学我唯唯诺诺,面对高数积分我重拳出击。
先算一道定积分来证明一下实力。

GPT的数学能力属于是介于好与差之间,呈现“拉胯二象性”。
对此GPT-4o给出的解释是:

实际感受也符合GPT的说法,一般情况下GPT可以提供一个大概的解题思路,但一到数字的具体运算上就拉胯了。

至于为啥好不好的大家都开始拿这个数学题来折磨AI了呢?
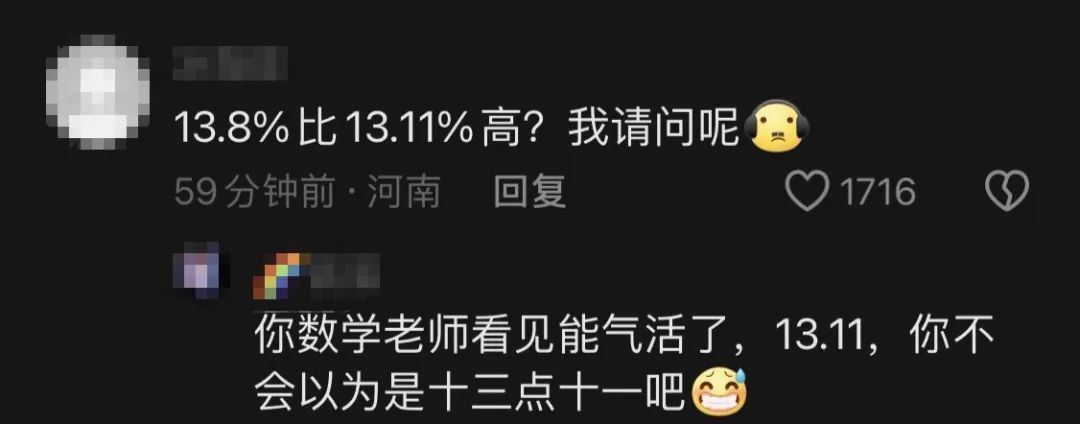
据说是《歌手》的第十期演出排名出来后,网友最大的关注点反而在孙楠13.8%的成绩在外国歌手13.11%之上。
有网友发出了灵魂拷问“13.8%比13.11%高?我请问呢?”
图片来源:抖音(下同)
这个问题直接给广大网友CPU干烧了,各种反串浑水摸鱼的满天飞。
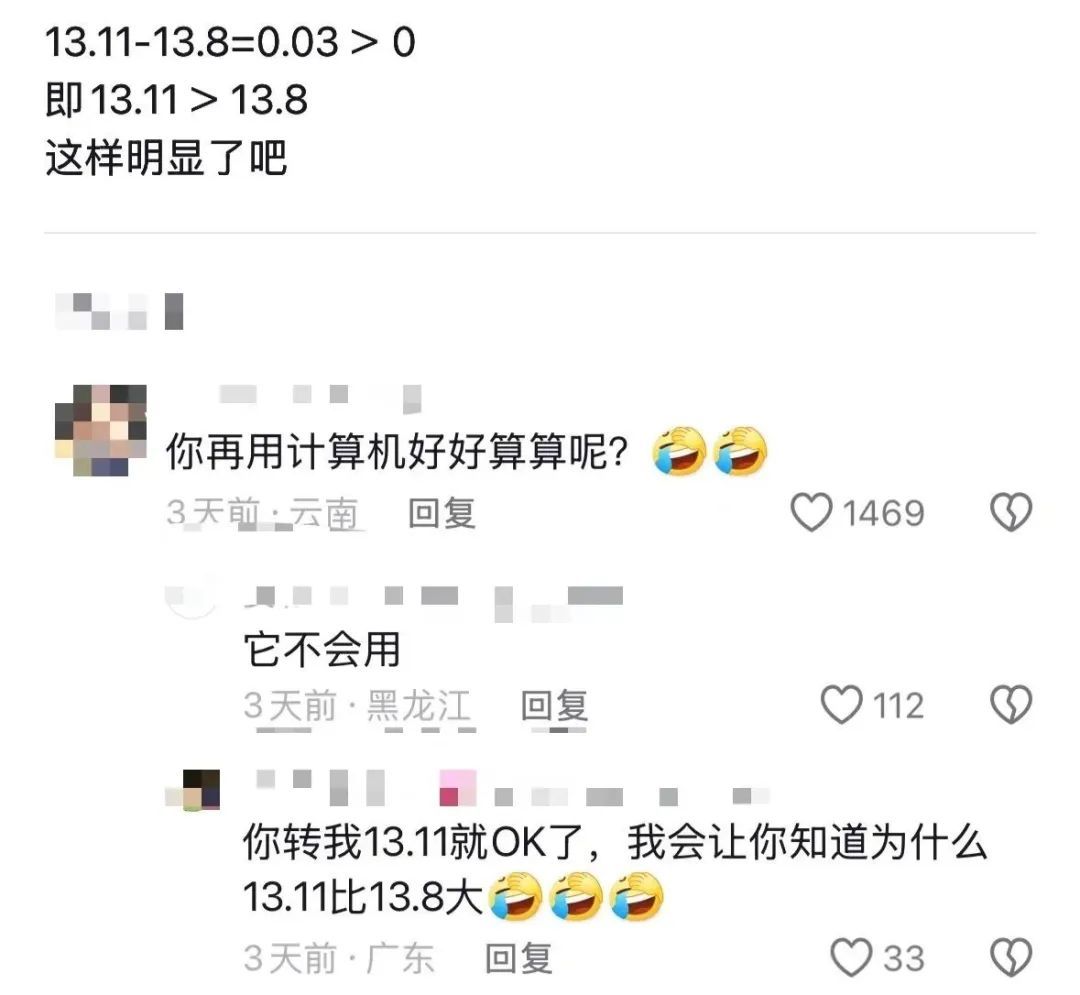
然后就有人想到了,可以去问问AI。
不过真要鸭鸭说,这些大模型给出的解释都弱爆了。
这张微信支付余额截图,直接杀死比赛堪称最直接的证明


你早这么教,鸭鸭不就会了吗?

友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com