FunAudioLLM团队 投稿
量子位 | 公众号 QbitAI
OpenAI迟迟不上线GPT-4o语音助手,其它音频生成大模型成果倒是一波接着一波发布,关键还是开源的。
刚刚,阿里通义实验室也出手了——
最新发布开源语音大模型项目FunAudioLLM,而且一次包含两个模型:SenseVoice和CosyVoice。
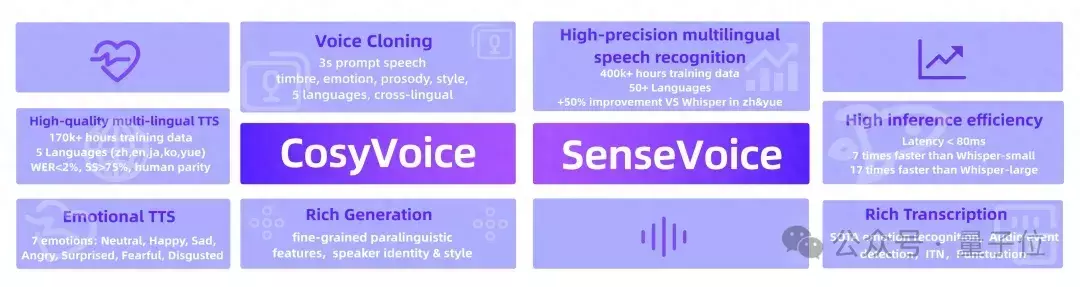
SenseVoice专注高精度多语言语音识别、情感辨识和音频事件检测,支持超过50种语言识别,效果优于Whisper模型,中文与粤语提升50%以上。
且情感识别能力强,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件检测,多方面测试拿下SOTA。
CosyVoice则专注自然语音生成,支持多语言、音色和情感控制,支持中英日粤韩5种语言的生成,效果显著优于传统语音生成模型。
仅需要3~10s的原始音频,CosyVoice即可生成模拟音色,甚至包括韵律、情感等细节,包括跨语种语音生成。
而且CosyVoice支持以富文本或自然语言的形式,对生成语音的情感、韵律进行细粒度的控制,生音频在情感表现力上得到明显提升。
话不多说,具体来看FunAudioLLM的用途以及效果展示。
FunAudioLLM能用来做什么?
基于SenseVoice和CosyVoice模型,FunAudioLLM可支持较多的人机交互应用场景,例如音色情感生成的多语言语音翻译、情绪语音对话、互动播客、有声读物等。
同音交传:模拟音色与情感的多语言翻译
通过结合SenseVoice、LLM以及CosyVoice,可以无缝地进行语音到语音的翻译(S2ST)。
需要注意的是,原始录音在文本中会以粗体显示。这种集成化的方法不仅提升了翻译的效率和流畅性,而且通过感知语音中的情感和语调,它能够在译文中复现原始语音的情感色彩,让对话的交流更加真实和动人。
无论是多语种的会议通译、跨文化的交流沟通,还是为非母语者提供即时语音翻译服务,这一技术都将大大缩小语言差距和沟通中的信息减损。

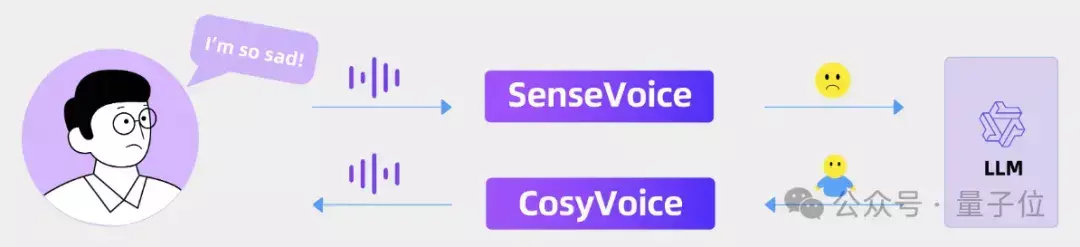
强情感交互的语音对话
通过融合SenseVoice、大语言模型(LLM)和CosyVoice,能够支持开发一款情感语音聊天应用程序。
当SenseVoice解析出情绪/情感/咳嗽等副语言信息后,大模型输出相对应的反馈情绪,并由CosyVoice生成出适当的声音情绪,从而完成舒适自然的对话交互过程。
在以下示例中,用户和助手的所有对话内容均由CosyVoice生成。
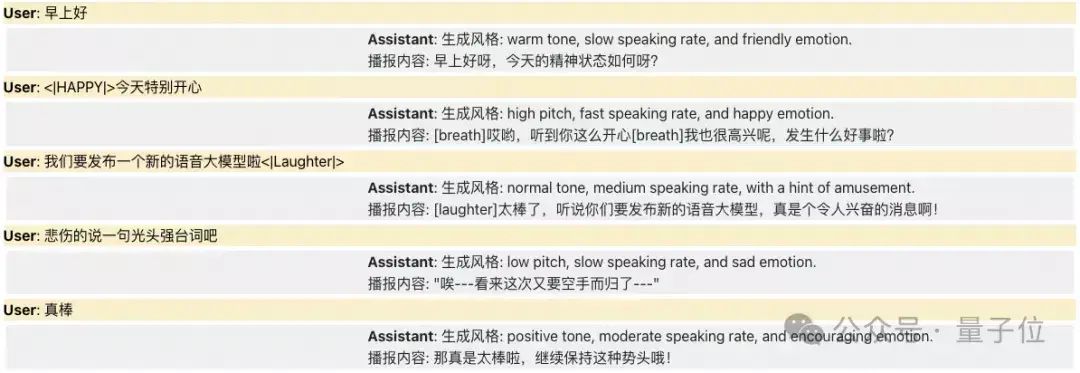
听起来是这样婶儿的:
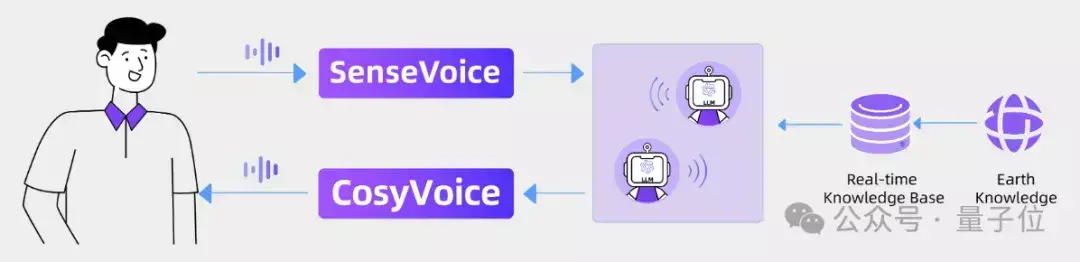
专属AI博客电台
通过将SenseVoice、基于LLM的具有实时世界知识的多代理系统和CosyVoice整合,能够创造一个互动式播客电台。
在这样的播客中,SenseVoice利用其高精度多语言语音识别功能,实时捕捉AI播客和用户的对话,甚至能够辨识环境音效和情感。
LLM多代理系统则能够处理SenseVoice提供的语音数据,实时更新世界知识库,确保话题和信息的及时性和准确性。在交互中,用户可以随时打断AI播客的对话,引导主题方向等,CosyVoice将用于生成AI播客的语音,具备多种语言、音色和情感的控制能力,为听众带来丰富多彩的听觉体验。

有声读物
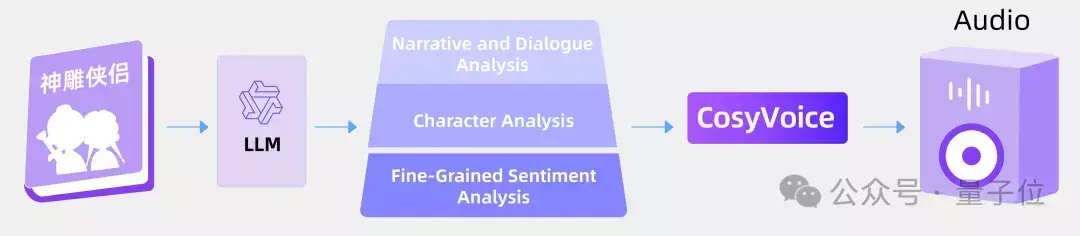
借助于LLM出色的分析能力,可对书籍内容进行结构化并识别其中的情感,再与CosyVoice的语音生成技术结合,能够实现具有更高表现力的有声读物。
LLM深入理解文本,捕捉每一个情感波动和故事弧线,而CosyVoice则将这些情感细腻地转化为语音,带有特定的情绪色彩和强调,为听众提供一个不仅丰富多彩而且情感充沛的听觉体验。
这样的有声读物不再是单一无变化的朗读,而是一场充满情感与生动表达的听觉盛宴,让每个故事和角色都栩栩如生。

FunAudioLLM技术原理解析
CosyVoice
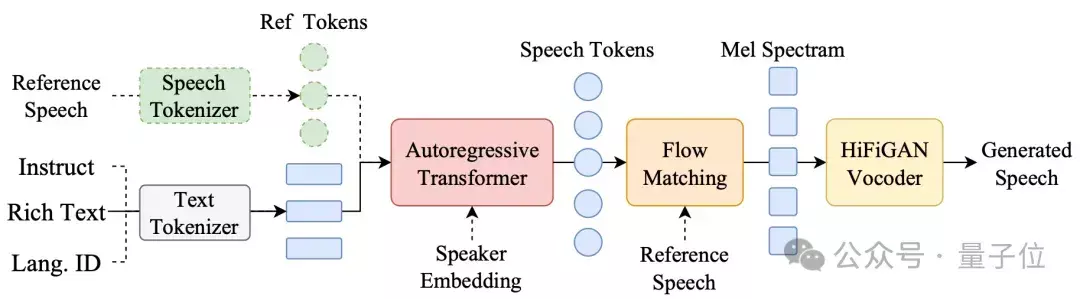
CosyVoice是一款基于语音量化编码的语音生成大模型。
它对语音进行离散化编码,并依托大模型技术,实现自然流畅的语音生成体验。与传统语音生成技术相比,CosyVoice具有韵律自然、音色逼真等特点。
CosyVoice支持多达5种语言,同时还支持以自然语言或富文本形式对生成语音进行情感等维度的细粒度控制。
研究团队提供了基模型CosyVoice-300M、经过SFT微调后的模型CosyVoice-300M-SFT、以及支持细粒度控制的模型CosyVoice-300M-Instruct,可满足不同场景下的使用需求。
生成语音客观指标

研究团队分别在开源中文数据集Aishell3以及英文数据集LibriTTS上,通过语音识别测试了合成音频的内容一致性。
通过与原始音频以及最近大火的ChatTTS对比,可以发现CosyVoice的合成音频在内容一致性上更高,并且没有很少存在幻觉额外多字的现象。
CosyVoice很好地建模了合成文本中的语义信息,达到了与人类发音人相当的水平。此外,通过对合成音频进行重打分,能够进一步降低识别的错误率,甚至在内容一致性和说话人相似度上超越人类。
情感控制能力
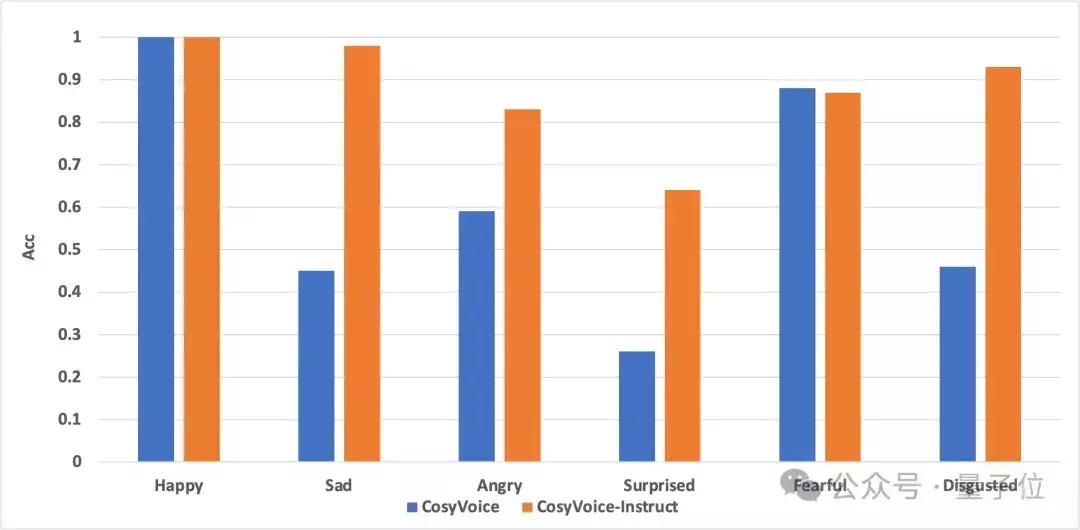
研究团队还使用预训练的情感分类模型评价了CosyVoice的情感控制能力,主要包括高兴/悲伤/生气/害怕/反感等5种高表现力的语音情感。
测试结果表明,CosyVoice-300M本身具备一定从文本内容中推断情感的能力,经过细粒度控制训练的模型CosyVoice-300M-Instruct在情感分类中的得分更高,具备更强的情感控制能力。
SenseVoice
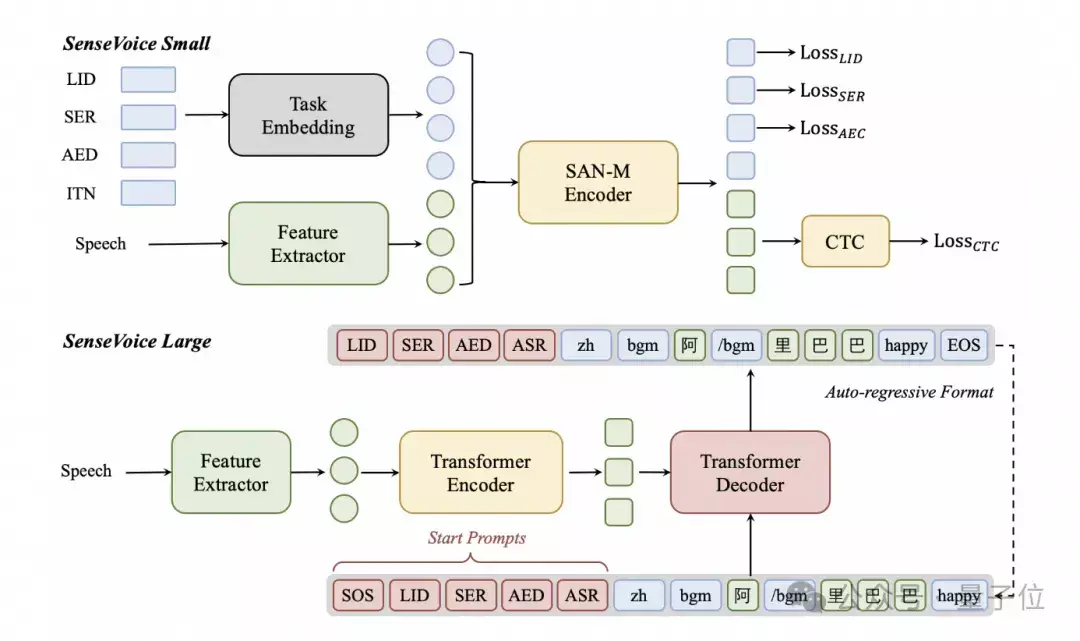
SenseVoice是一个基础语音理解模型,具备多种语音理解能力,涵盖了自动语音识别(ASR)、语言识别(LID)、情感识别(SER)以及音频事件检测(AED)。
该模型旨在提供全面的语音处理功能,从而支持构建更复杂的语音交互系统。
SenseVoice-Small是一款仅含编码器的轻量级基础语音模型,设计用于快速语音理解。它可以快速处理语音数据,并在有需要时迅速做出响应,适用于对延迟敏感的应用场合,如实时语音交互系统。
SenseVoice-Large则是一个包含编码器和解码器的大型基础语音模型。这个版本的SenseVoice专注于更精确的语音理解,拥有对更多语言的支持能力。它适合于对识别精度有更高要求的场景,可以处理更复杂的语音输入,并生成更为准确的结果。
多语言语音识别性能
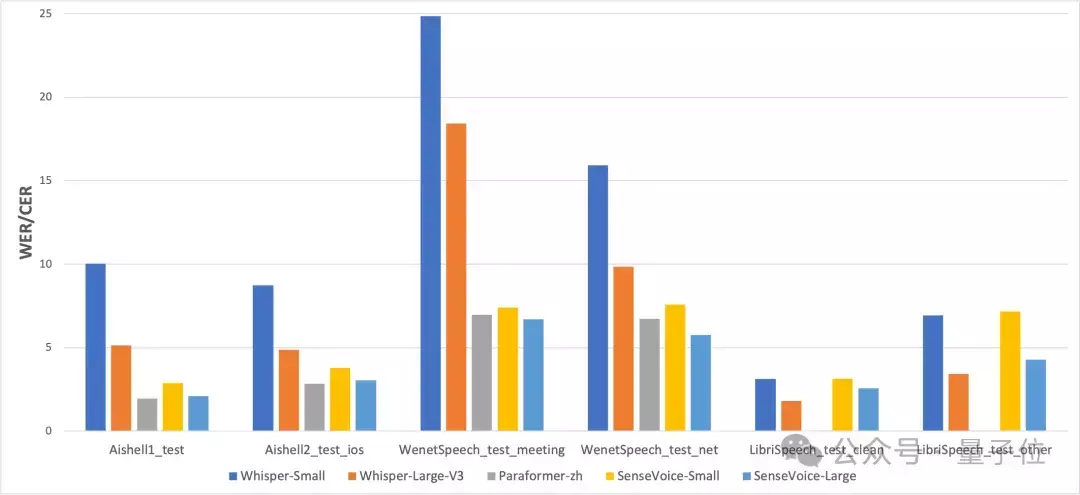

研究团队在开放源数据集上比较了SenseVoice和Whisper的多语言识别性能和推理效率,包括AISHELL-1、AISHELL-2、Wenetspeech、Librispeech和Common Voice。
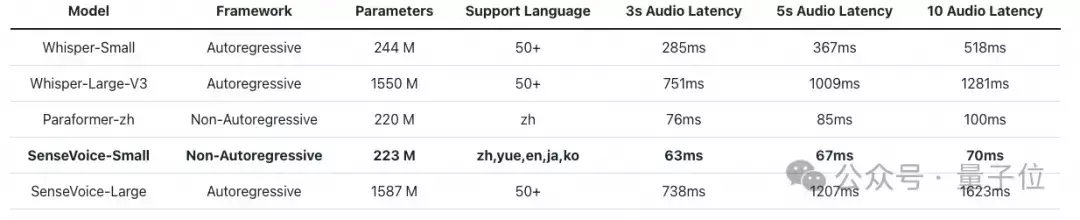
推理效率评估是在A800机器上进行的。SenseVoice-Small采用非自回归端到端架构,由此带来的推理延迟极低——相比之下,它比Whisper-Small快7倍,比Whisper-Large快17倍。
语音情感识别性能

SenseVoice也可以用于离散情绪识别,目前支持的情绪类型包括高兴、悲伤、愤怒和中性。
团队在7个流行的情绪识别数据集上对其进行了评估。即使没有对目标语料库进行微调,SenseVoice-Large都能在大多数数据集上达到或超越最新的最佳结果(SOTA)。
音频事件检测性能
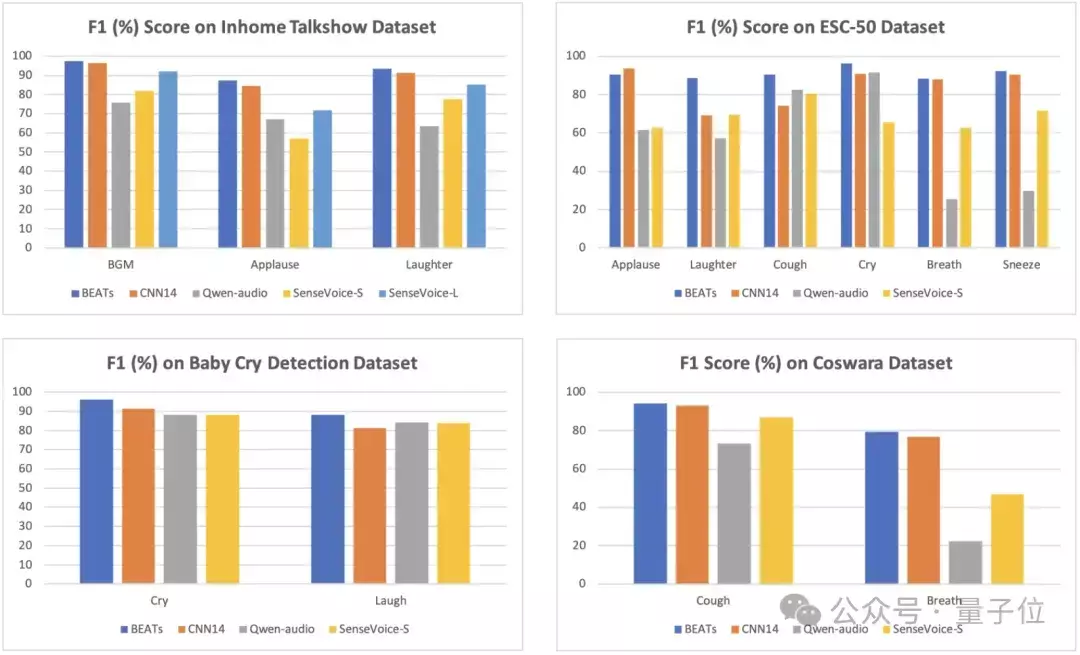
SenseVoice-Small与SenseVoice-Large模型都能在语音中检测音频事件,包括音乐、掌声和笑声。
SenseVoice-Large模型除了能够预测音频事件的类型,还能精准识别事件发生的起始和结束位置。
与之相比,SenseVoice-Small模型虽然仅能预测音频中发生的事件类型(仅限于一个事件),但它能够检测到更多种类的事件,诸如在人机互动过程中可能出现的咳嗽、打喷嚏、呼吸和哭泣等。
目前,与SenseVoice和CosyVoice相关的模型已在ModelScope和Huggingface上开源,同时在GitHub上发布了相应的训练、推理和微调代码。
FunAudioLLM:https://github.com/FunAudioLLM
CosyVoice开源仓库:https://github.com/FunAudioLLM/CosyVoiceCosyVoice在线体验:https://www.modelscope.cn/studios/iic/CosyVoice-300MSenseVoice开源仓库:https://github.com/FunAudioLLM/SenseVoiceSenseVoice在线体验:https://www.modelscope.cn/studios/iic/SenseVoice— 完 —
量子位 QbitAI · 头条号签约
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com